به تعبیر Andreessen Horowitz، هوش مصنوعی مولد، به ویژه در بخش متن به هنر، دنیا را می خورد. حداقل، سرمایهگذاران اینطور معتقدند – با قضاوت با میلیاردها دلاری که برای استارتآپهای توسعهدهنده هوش مصنوعی که متن و تصاویر را از طریق درخواستها ایجاد میکند، سرمایهگذاری کردهاند.
Big Tech روی راهحلهای هنری مولد هوش مصنوعی خود سرمایهگذاری میکند، چه از طریق مشارکت با استارتآپهای فوقالذکر یا R&D داخلی. (نگاه کنید به: همکاری مایکروسافت با OpenAI برای Image Creator.) Google، با استفاده از شاخه تحقیق و توسعه قوی خود، تصمیم گرفته است مسیر دوم را طی کند و کار خود را در زمینه هوش مصنوعی مولد برای رقابت با پلتفرمهایی که در حال حاضر وجود دارد، تجاری کند.
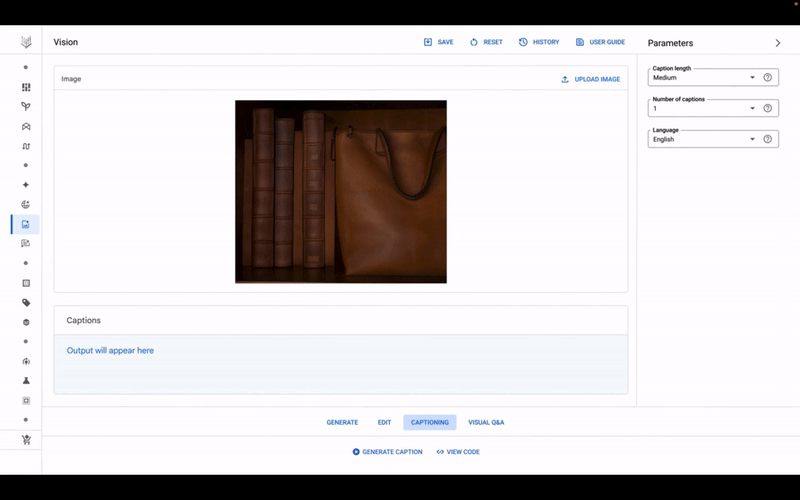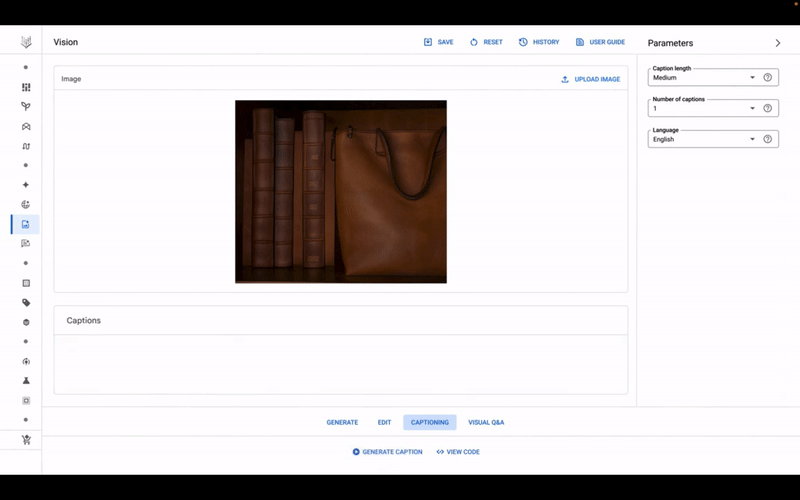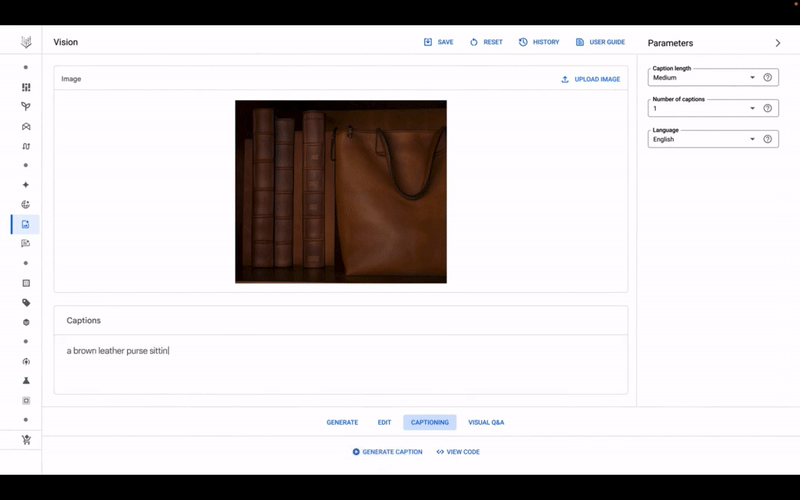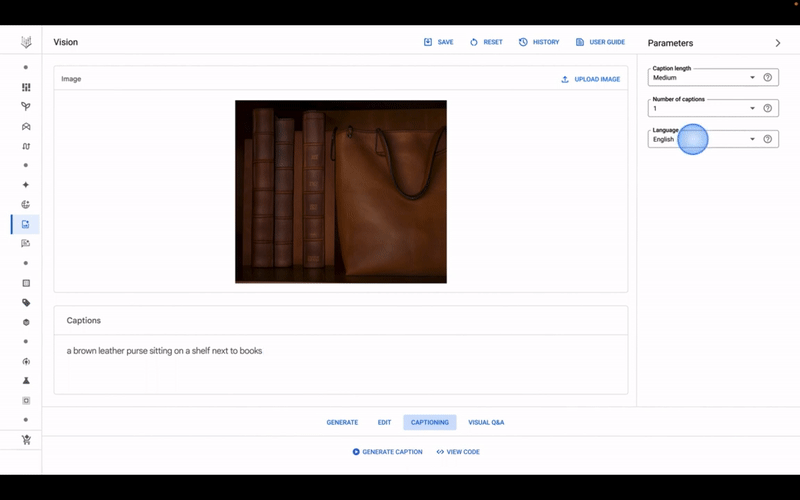
امروز در کنفرانس سالانه توسعهدهندگان I/O، گوگل مدلهای هوش مصنوعی جدیدی را معرفی کرد که به سمت Vertex AI، سرویس هوش مصنوعی کاملاً مدیریت شدهاش، از جمله مدل تبدیل متن به تصویر به نام Imagen، حرکت میکنند. Imagen، که گوگل در نوامبر گذشته از طریق برنامه AI Test Kitchen پیشنمایش آن را انجام داد، میتواند تصاویر را تولید و ویرایش کند و همچنین برای تصاویر موجود زیرنویس بنویسد.
ننشاد باردولیوالا، مدیر Vertex AI در Google Cloud در یک مصاحبه تلفنی به TechCrunch گفت: «هر توسعهدهندهای میتواند با استفاده از Google Cloud از این فناوری استفاده کند. “نیازی نیست که دانشمند داده یا توسعه دهنده باشید.”
تصویر در Vertex
شروع کار با Imagen در Vertex در واقع یک فرآیند نسبتاً ساده است. یک رابط کاربری برای این مدل از چیزی که Google آن را باغ مدل مینامد، در دسترس است، مجموعهای از مدلهای توسعهیافته توسط Google در کنار مدلهای منبع باز مدیریتشده. در داخل UI، مشابه پلتفرمهای هنری مولد مانند MidJourney و Nightcafe، مشتریان میتوانند درخواستهایی را وارد کنند (مثلاً “یک کیف دستی بنفش”) تا Imagen تعداد انگشت شماری از تصاویر نامزد تولید کند.
ابزارهای ویرایش و درخواستهای بعدی، تصاویر تولید شده توسط Imagen را اصلاح میکنند، به عنوان مثال، رنگ اشیاء نشان داده شده در آنها را تنظیم میکنند. Vertex علاوه بر تنظیم دقیق که به مشتریان امکان می دهد Imagen را به سمت سبک ها و ترجیحات خاصی هدایت کنند، ارتقاء مقیاس را برای وضوح تصاویر ارائه می دهد.
همانطور که قبلا اشاره شد، Imagen همچنین میتواند برای تصاویر زیرنویس ایجاد کند و به صورت اختیاری آن زیرنویسها را با استفاده از Google Translate ترجمه کند. برای مطابقت با قوانین حفظ حریم خصوصی مانند GDPR، تصاویر تولید شده که ذخیره نمی شوند ظرف 24 ساعت حذف می شوند. باردولیوالا می گوید.
ما شروع به کار با هوش مصنوعی مولد و تصاویر آنها را برای مردم بسیار آسان می کنیم. او اضافه کرد.
البته، انبوهی از چالشهای اخلاقی و قانونی در ارتباط با همه اشکال هوش مصنوعی مولد وجود دارد – مهم نیست چقدر رابط کاربری صیقلی است. مدلهای هوش مصنوعی مانند Imagen «یاد میگیرند» با «آموزش» روی تصاویر موجود، تصاویری را از پیامهای متنی تولید کنند، که اغلب از مجموعه دادههایی میآیند که با تراش کردن وبسایتهای میزبان تصویر عمومی به هم خراشیده شدهاند. برخی از کارشناسان پیشنهاد میکنند که مدلهای آموزشی با استفاده از تصاویر عمومی، حتی آنهایی که دارای حق چاپ هستند، تحت دکترین استفاده منصفانه در ایالات متحده قرار میگیرند، اما این موضوعی است که بعید به نظر میرسد به این زودی حل شود.

مدل Imagen گوگل در عمل، در Vertex AI.
در عین حال، دو شرکت پشت ابزارهای هنری محبوب هوش مصنوعی، Midjourney و Stability AI، در تیررس یک پرونده قانونی هستند که ادعا می کند با آموزش ابزارهای خود بر روی تصاویر خراشیده شده در وب، حقوق میلیون ها هنرمند را نقض کرده اند. تامینکننده تصاویر استوک Getty Images به دلیل استفاده از میلیونها تصویر از سایت خود بدون مجوز برای آموزش مدل تولیدکننده هنر Stable Diffusion، هوش مصنوعی Stability AI را جداگانه به دادگاه برده است.
من پرسیدم باردولیوالا آیا مشتریان Vertex باید نگران باشند که Imagen ممکن است در مورد مطالب دارای حق چاپ آموزش دیده باشد. قابل درک است که اگر چنین بود، ممکن است از استفاده از آن منصرف شوند.
باردولیوالا صراحتاً نگفت که Imagen در مورد تصاویر دارای علامت تجاری آموزش ندیده است – فقط گوگل “بررسی های گسترده حاکمیت داده” را انجام می دهد تا “داده های منبع” را در مدل های خود بررسی کند تا اطمینان حاصل کند که آنها “عاری از ادعای حق نسخه برداری” هستند. (با توجه به این که Imagen اصلی بر روی یک مجموعه داده عمومی، LAION، که دارای آثار دارای حق چاپ شناخته شده است، آموزش داده شده است، زبان محافظت شده چندان تعجب آور نیست.)
“ما باید اطمینان حاصل کنیم که کاملاً در تعادل احترام به همه قوانین مربوط به اطلاعات حق چاپ هستیم.” باردولیوالا ادامه داد. ما با مشتریان کاملاً واضح هستیم که مدلهایی را در اختیار آنها قرار میدهیم که میتوانند از آن در کار خود استفاده کنند و اینکه IP تولید شده از مدلهای آموزشدیدهشان را به شیوهای کاملاً ایمن در اختیار دارند.»
داشتن آی پی موضوع دیگری است. حداقل در ایالات متحده، روشن نیست که آیا هنر تولید شده توسط هوش مصنوعی دارای حق چاپ است یا خیر.
یک راه حل – نه برای مشکل مالکیت، بلکه برای سوالات مربوط به داده های آموزشی دارای حق چاپ – این امکان را به هنرمندان می دهد که به طور کلی از آموزش هوش مصنوعی “انصراف دهند”. استارتآپ هوش مصنوعی Spawning در تلاش است تا استانداردها و ابزارهای گستردهای را برای انصراف از فناوری هوش مصنوعی مولد ایجاد کند. Adobe در حال پیگیری مکانیسمها و ابزارهای انصراف خود است. DeviantArt نیز همینطور است، که در ماه نوامبر یک حفاظت مبتنی بر تگ HTML راه اندازی کرد تا ربات های نرم افزاری را از خزیدن در صفحات برای تصاویر منع کند.
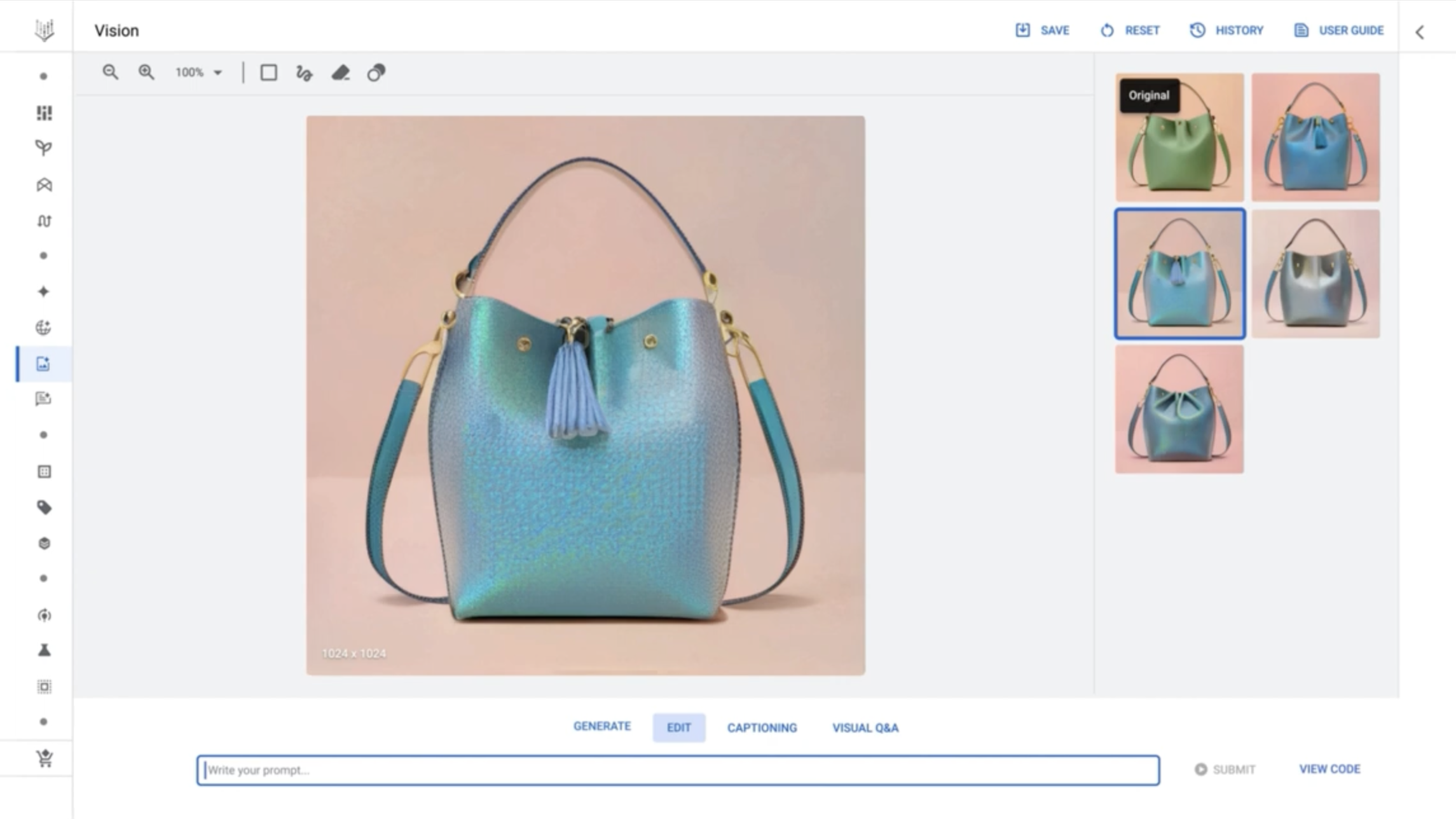
اعتبار تصویر: گوگل
گوگل گزینه انصراف ارائه نمی دهد. (منصفانه بگوییم، یکی از رقبای اصلی آن، OpenAI نیز چنین نیست.) باردولیوالا نگفت که آیا این ممکن است در آینده تغییر کند یا خیر، فقط این که گوگل است.به شدت نگران این است که مطمئن شود که مدلها را به روشی «اخلاقی و مسئولیتپذیر» آموزش میدهد.
فکر میکنم این مقدار کمی غنی است، از شرکتی میآید که هیئت علمی اخلاق هوش مصنوعی بیرونی را لغو کرد، محققان برجسته اخلاق هوش مصنوعی را مجبور به اخراج کرد و انتشار تحقیقات هوش مصنوعی را برای “رقابت و حفظ دانش در خانه” کاهش داد. اما تفسیر کنید سخنان باردولیوالا همانطور که می خواهید.
من هم پرسیدم باردولیوالا درباره گامهایی که گوگل برای محدود کردن میزان محتوای سمی یا مغرضانه ایجاد میکند، در صورت وجود، انجام میدهد – مشکل دیگری در سیستمهای هوش مصنوعی مولد. اخیراً، محققان استارتآپ Hugging Face و دانشگاه لایپزیگ ابزاری را منتشر کردند که نشان میدهد مدلهایی مانند Stable Diffusion و OpenAI’s DALL-E 2 تصاویری از افراد سفیدپوست و مردانه تولید میکنند، بهویژه زمانی که از آنها خواسته میشود افرادی را در موقعیتهای قدرتمند به تصویر بکشند.
Bardoliwalla پاسخ دقیق تری برای این سوال آماده کرده بود و ادعا می کرد که هر فراخوانی API به مدل های مولد میزبان Vertex از نظر “ویژگی های ایمنی” از جمله سمیت، خشونت و فحاشی ارزیابی می شود. Bardoliwalla گفت که Vertex مدلها را بر اساس این ویژگیها امتیاز میدهد و برای دستههای خاص، پاسخ را مسدود میکند یا به مشتریان اجازه میدهد چگونه ادامه دهند.
«ما از ویژگیهای مصرفکننده خود حس خوبی نسبت به نوع محتوا داریم که ممکن است آن نوع محتوایی نباشد که مشتریان ما به دنبال این مدلهای هوش مصنوعی مولد برای تولید هستند.» او ادامه داد. “این زمینهای برای سرمایهگذاری قابل توجه و همچنین رهبری بازار برای Google است – برای اینکه مطمئن شویم مشتریان ما میتوانند نتایجی را که به دنبال آن هستند تولید کنند که به ارزش نام تجاری آنها لطمه یا لطمه وارد نمیکند.»
برای این منظور، گوگل یادگیری تقویتی از بازخورد انسانی (RLHF) را به عنوان یک سرویس مدیریت شده در Vertex راهاندازی میکند، که ادعا میکند به سازمانها کمک میکند عملکرد مدل را در طول زمان حفظ کنند و مدلهای ایمنتر – و بهطور قابل اندازهگیری دقیقتر – را در تولید به کار ببرند. RLHF، یک تکنیک محبوب در یادگیری ماشینی، یک «مدل پاداش» را مستقیماً از بازخورد انسانی آموزش میدهد، مانند درخواست از کارکنان قراردادی برای رتبهبندی پاسخها از یک ربات چت هوش مصنوعی. سپس از این مدل پاداش برای بهینه سازی یک مدل هوش مصنوعی مولد در امتداد خطوط Imagen استفاده می کند.
اعتبار تصویر: گوگل
Bardoliwalla می گوید که مقدار تنظیم دقیق مورد نیاز از طریق RLHF به دامنه مشکلی که مشتری برای حل آن تلاش می کند بستگی دارد. بحثهایی در دانشگاه وجود دارد که آیا RLHF همیشه رویکرد درستی است یا خیر – برای اولین بار، استارتآپ هوش مصنوعی Anthropic استدلال میکند که اینطور نیست، تا حدی به این دلیل که RLHF میتواند مستلزم استخدام تعداد زیادی پیمانکار کمدرآمد باشد که مجبور به رتبهبندی محتوای بسیار سمی هستند. اما گوگل احساس متفاوتی دارد.
“با خدمات RLHF ما، مشتری می تواند یک روش و مدل را انتخاب کند و سپس به پاسخ هایی که از مدل می آید امتیاز دهد.” باردولیوالا گفت. “یک بار آنها این پاسخها را به سرویس یادگیری تقویتی ارسال کنید، این مدل را به گونهای تنظیم میکند که پاسخهای بهتری را ایجاد کند که با … آنچه سازمان به دنبال آن است، همسو باشد.
مدل ها و ابزارهای جدید
گوگل امروز اعلام کرد که فراتر از Imagen، چندین مدل هوش مصنوعی مولد دیگر هم اکنون برای مشتریان انتخابی Vertex در دسترس هستند: Codey و Chirp.
Codey، پاسخ گوگل به Copilot GitHub، می تواند کد را به بیش از 20 زبان از جمله Go، Java، Javascript، Python و Typescript تولید کند. Codey میتواند چند خط بعدی را بر اساس زمینه کد وارد شده در یک اعلان پیشنهاد کند یا مانند ChatGPT OpenAI، این مدل میتواند به سؤالات مربوط به اشکالزدایی، اسناد و مفاهیم برنامهنویسی سطح بالا پاسخ دهد.

اعتبار تصویر: گوگل
در مورد Chirp، این یک مدل گفتاری است که میلیونها ساعت صدا را آموزش داده و از بیش از 100 زبان پشتیبانی میکند و میتواند برای نوشتن شرح ویدیوها، ارائه کمک صوتی و به طور کلی قدرت بخشیدن به طیف وسیعی از وظایف گفتاری و برنامهها استفاده شود.
گوگل در یک اعلامیه مرتبط در I/O، Embeddings API را برای Vertex در پیشنمایش راهاندازی کرد، که میتواند دادههای متن و تصویر را به نمایشهایی به نام بردار تبدیل کند که روابط معنایی خاصی را ترسیم میکند. گوگل می گوید که از آن برای ایجاد قابلیت جستجوی معنایی و طبقه بندی متن مانند ربات های گفتگوی پرسش و پاسخ بر اساس داده های سازمان، تجزیه و تحلیل احساسات و تشخیص ناهنجاری استفاده می شود.
به گفته گوگل، Codey، Imagen، Embeddings API برای تصاویر و RLHF در Vertex AI برای «تستکنندگان مورد اعتماد» در دسترس هستند. در همین حال، Chirp، Embeddings API و Generative AI Studio، مجموعهای برای تعامل و استقرار مدلهای هوش مصنوعی، در پیشنمایش در Vertex برای هر کسی که حساب Google Cloud دارد، قابل دسترسی است.
